ALLFED Integrated Food System Model
![]()
![]()
![]()
An integrated food supply model for resilient foods in nuclear winter
Run the model
- You can create a variety of different scenarios with this model. A collection of possible scenarios are already available in the scenarios folder (e.g.
run_model_with_resilient_foods.py). Examples of usage can be found in the scripts folder. Resulting pptx can be found in results/large_reports/. If you don't wish to run these results yourself, you can find more pregenerated results in the Zenodo repository (https://zenodo.org/record/7039924).
Running on command line
(See Dependencies section first)
Results from the paper can be rerun using the following command:
python3 plot_manuscript_figures.py rerun all
You can always just run
python3 plot_manuscript_figures.py
To see how to run fewer plots, load plots you already ran, or show specific results from the paper.
Individual scenarios, or a series of scenarios of interest, can be specified in the scenarios/ folder.
./run_scenarios_from_yaml.sh True False True argentina.yaml
This shows a series of stackplots of argentina with no food trade, including animal slaughter, feed, and food available to humans after waste each month. The scenarios shown are:
- Baseline net production (continued feed/biofuel, normal climate)
- Baseline gross production (shut off feed/biofuel, normal climate)
- Nuclear winter net production (continued feed/biofuel, 150 Tg nuclear winter)
- Nuclear winter with reduced feed/waste (continued feed/biofuel, nuclear winter, reduced waste)
- Nuclear winter with resilient foods (continued feed/biofuel, nuclear winter, reduced waste, resilient foods)
- Nuclear winter with resilient foods & more area (continued feed/biofuel, nuclear winter, reduced waste, resilient foods, cropland expansion)
The first argument is whether to show plotted simulation results for the different rounds of optimization. The second argument is whether to show a map of percent people fed for all countries, and shows at the end for each type of scenario specified in the yaml file. The third argument should be set to False unless you are running the model from the web interface.
Rounds of optimization: Round1 is zero feed/biofuel for ascertaining minimum human needs that can be satisfied, Round2 determines the amount of feed and biofuel that could be used to optimally produce feed and optionally biofuel, and the Round3 finally combines the appropriate amount of feed and biofuel used while still satisfying human minimum caloric needs. You can alter the plots shown by commenting out display code in scenarios/run_scenario.py display_results_of_optimizer_round function calls.
To run these scenarios for a specific country, you can create a new yaml file with a specific country specified in the yaml file. For example, to run Oman, you can add the following to the yaml:
settings:
countries: "OMN"
Where "OMN" is the 3 letter iso3 code for Oman.
If you name this new yaml file for the scenarios as: "your_yaml_file_here.yaml", then you would run:
./run_scenarios_from_yaml.sh True False your_yaml_file_here.yaml
To see the results for Oman baseline, nuclear winter, and nuclear winter with resilient foods.
More Details
See the zenodo repository for more results and reports: https://zenodo.org/record/7039924
How the model works in general
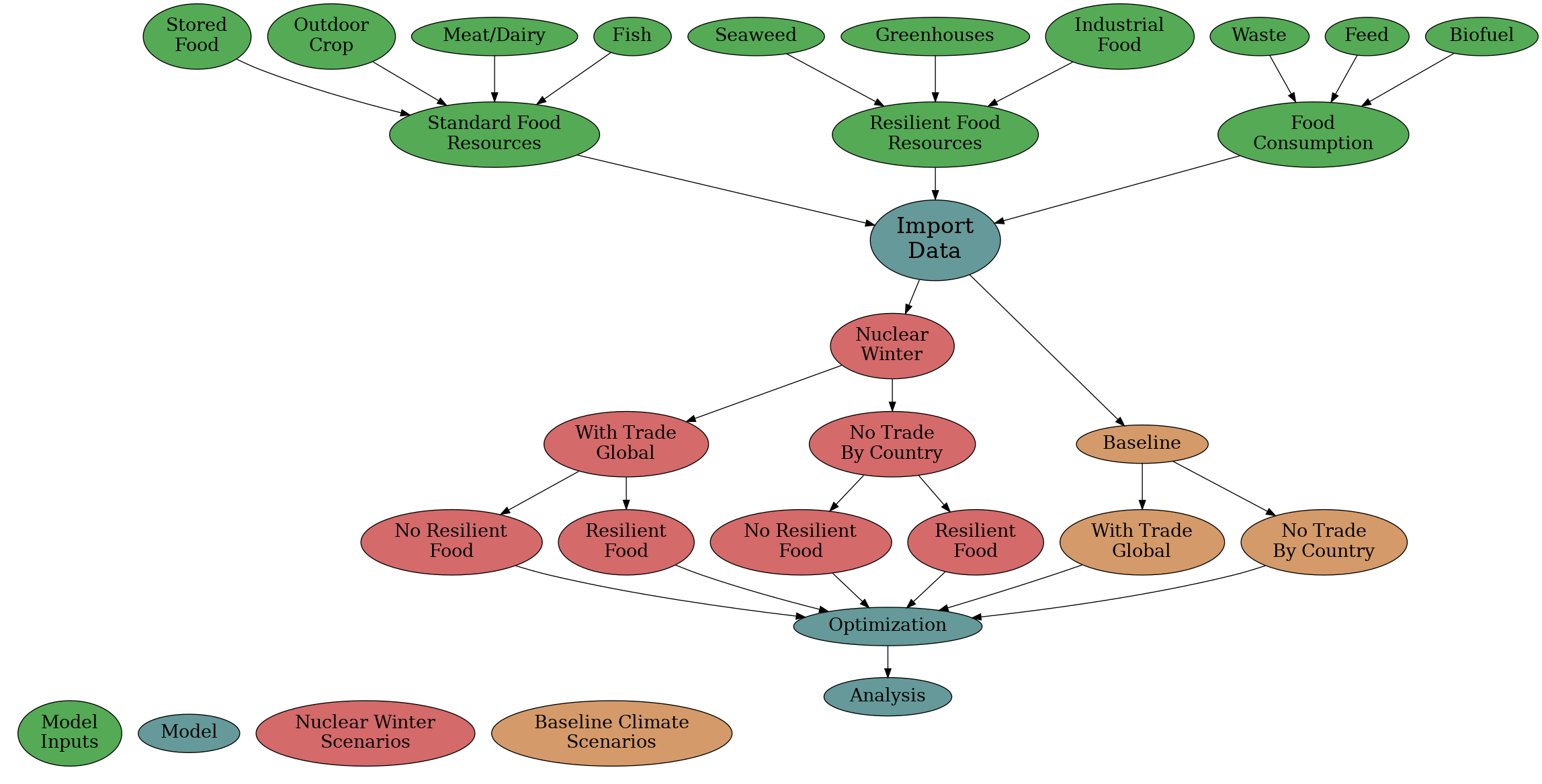
more details

.svg)
Dependency management with Anaconda
The integrated model is written in python 3, ensure you have some version of python3, although it has only been tested with python 3.9 or later. Then, install the required packages using conda or miniconda:
You'll also need to install conda or miniconda, micromamba, or similar.
See https://docs.anaconda.com/anaconda/install/index.html for installation instructions.
Once the program is installed on your device, set up a separate environment for the project (do not use your base environment). This step and the following can be done in two ways: - using the GUI or - using the Anaconda Prompt. For people new to coding the GUI is more intuitive.
GUI
- Open the Anaconda Navigator.
- Select the tap "Environments".
- Click "Import" and select the "environment.yml" file from the repository and name the new environment. All dependencies will be installed automatically.
Anaconda Prompt
- Open Anaconda Prompt.
- Type in the following line:
conda env create -f environment.yml
The dependencies will be installed automatically and the environment will be name intmodel.
If you close out the terminal and open it later you will want to activate the environment again using
conda activate intmodel
For both versions: Code from this project will only run smoothly when opened in the new environment and when the working directory is set to the path location of the repository on your machine.
Regenerate documentation
python3 automate_mkdocs.py
gendocs --config mkgendocs.yml
mkdocs serve
Then navigate to http://127.0.0.1:8000/ in your web browser.
Detailed Explanation of Files and Folders in this Repository
Below we explain all of the folders and files used for getting data, processing data, running simulations, then displaying and saving results of models.
Files purely for mentation or creating the python environment are not included below.
Directory Structure
├── data/
│
│ All the tabulated data used for the repository, as well as intermediary
│ processed results from import scripts. Also contains data explaining
│ assumptions of the model in the Supplemental_Data.xlsx file.
│
├── results/
│
│ Outputs of the model including figures and pptx generated reports.
│
├── scripts/
│
│ Convenient scripts used to run sets of python scripts.
│
├── src/
│
│ All of the code used to model the food system and to run simulations.
│
data/
All data for the use of generating scenarios is contained in this directory, with the exception that some aggregate global constants for the food system are stored in the src/scenarios/scenarios.py file. (Note: currently getting rid of "magic numbers" in other files, but it is a long process)
resilient_food_primary_results.npy, no_resilient_food_primary_results.npy
These are used for plotting data from src/scenarios/plot_primary_food.py.
Supplemental_Data.xlsx
This is part of the raw data imported in the case of Nutrition, or used directly for estimating the performance of crop relocation or expected diet availability, as well as crop seasonality.
The spreadsheet contains the following tabs:
- Summary of field margins
- Cost modelling
- Diet affordability
- Crop years
- Production & stocks seasonality
- Crop Model Results
- Crop Model ASRS Relocation Estimate
- Crop Model No Relocation
- Crop Model 2005
- Production 2005
- Production 2005 Raw
- Nutrition
data/no_food_trade/
Contains data used to run the country-by-country no food trade model.
processed_data/
All of the CSV files in this folder are generated by running the scripts/run_all_imports.sh file. They contain data in standard format for each country on values of interest for the food system models (for no food trade scenarios).
raw_data/
All data files used for each country in the no food trade scenarios, directly from the data source (before processing to make standard format). Processing of these files happens using the import files in /src/import_scripts_no_food_trade/ directory, which can in turn be called all at once using the scripts/run_all_imports.sh script.
computer_readable_combined.csv
The ultimate result from running all the import scripts in src/import_scripts_no_food_trade, (also accomplished using scripts/run_all_scripts.py). In particular, the src/import_scripts_no_food_trade/import_food_data.py file creates this by merging the csvs into a dataframe then exporting the result to this csv.
data/no_food_trade/raw_data/
Raw data files for each country in the no food trade scenarios, directly from the data source (before processing to make standard format). Processing of these files happens using the import files in /src/import_scripts_no_food_trade/ directory, which can in turn be called all at once using the scripts/run_all_imports.sh script.
FAOSTAT_*_.CSV
Data files imported directly from FAOSTAT for the year in question.
Integrated Model With No Food Trade.xlsx
The spreadsheet is used as a remaining set of data pertaining to no food trade scenarios, which is imported in addition to raw FAOSTAT data to create the final computer_readable_code.csv file.
Contains the following tabs: * Population * Food waste * Outdoor crop Production Seasonality * Outdoor Crop Production Baseline * Outdoor Crop Production NW * Food Stocks * Seafood - excluding seaweeds * Grazing * Seaweed * Cellulosic Sugar * Greenhouses * Methane SCP * Combined
rutgers_nw_production_raw.csv
Raw data provided by the Rutgers Toon group from Xia et al publication regarding grasses and staple crops (spring wheat, maize, soybean, rice) fractional crop yields to baseline in a 150 tg nuclear winter scenario.
results/
Outputs of the model including figures and pptx generated reports.
large_reports/
Reports generated with the run_model_no_trade_baseline.py, run_model_no_trade_no_resilient_foods.py, and run_model_no_trade_with_resilient_foods.py in src/scenarios/.
Figure_4/
Diagrammatic flow chart of the integrated model.
*.fig
Figures produced by running some src/scenarios/ files. The last stage of figure generation (plotting itself) always occurs in the src/utilities/plotter.py file.
scripts/
Convenient scripts used to run sets of python scripts.
create_all_no_trade_scenario_pptx.sh
Generates a full set of results in results/large_reports/ by running run_model_no_trade scripts in src/scenarios/, using both the "single" and "multi" arguments.
run_all_imports.sh
This script creates all the imported .csv files in the data/no_food_trade/processed_data folder, by running all the import_*_csv.py scripts in src/import_scripts_no_food_trade/. It's required to run this for importing all the food system input data before running simulations if no_food_trade scenarios are being run.
src/
All of the code used to model the food system and to run simulations
food_system/
Called by the compute_parameters function in src/optimizer/parameters.py, each function represents a different part of the food system.
import_scripts_no_food_trade/
This is required to be run before other files in src/ in order to import raw data into a usable format for other files in src/. It is a set of scripts that are run to import food system data, typically by the scripts/run_all_imports.sh file. These create the imported .csv files in the data/no_food_trade/processed_data folder. It's required to run this for importing all the food system input data before running simulations for no_food_trade scenarios.
src/optimizer/
The optimizer folder runs the following sequence in order for every scenario: compute_parameters, run_optimizer, extract_results, interpret_results, validate_results. The parameters.py file also imports all the src/food_system category-specific calculations. The results of parameters.py are sent to the optimizer.py through the constants_out variable.
Optimization in optimizer uses the PuLP linear optimizer to optimally satisfy the series of constraints used in that model.
src/scenarios/
Running a script in scenarios is done after completing import of the scripts, if no_food_trade scenarios are being run. The scenarios are all either involving full food trade or no food trade between trading blocs, as determined by the trading bloc data in no_food_trade/computer_readable_combined.csv and globally-aggregated data stored in scenarios.py.
Utility files used to specify the scenarios are: scenarios.py
Finally the results are returned from run_scenario back up the call chain in reverse order.
utilities/
various useful utilities that are called elsewhere in the program, that do not serve any core function for the modelling. Notably, all the plotting code is located in the utilities directory.